Master Node와 Worker Node 생성 및 기본 설정
1. k8s-m 설치(ubuntu-20.04.2-live-server-amd64.iso)
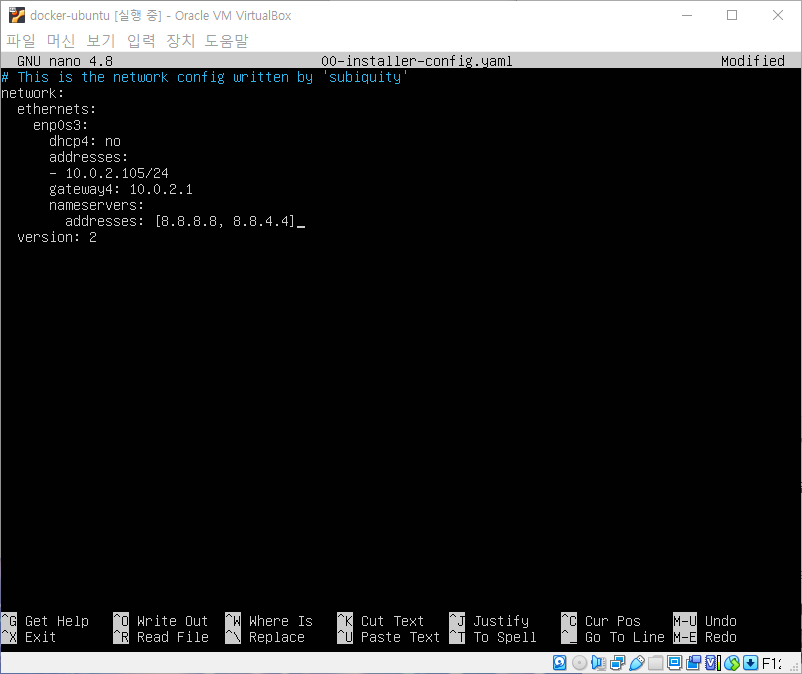
2. k8s-m IP 주소 설정(netplan apply & shutdown) 및 스냅샷
3. k8s-m 클론떠서 k8s-w1, k8s-w2, k8s-w3 생성
4. 워커 노드 하나씩 접속하여 IP 주소 설정(netplan apply & shutdown) 및 스냅샷
* Master는 메모리 4GB, CPU 2개로 잡고 Worker는 메모리 2GB, CPU 1개로 잡는다.
kubeadm 으로 k8s 클러스터 생성 & CNI 설치
# 마스터 노드에서 클러스터 초기화 (K8s version v1.21.1)
kubeadm init --apiserver-advertise-address 192.168.79.200 --pod-network-cidr=172.16.0.0/16 --service-cidr 10.10.0.0/16
# 출력 내용 중 아래 2줄을 워커 노드에서 입력
kubeadm join 192.168.79.200:6443 --token t9fzfv.dxvtsz75l418ojf1 \
--discovery-token-ca-cert-hash sha256:055a3aef6fb8e930bff50da508007748fe97d3683c312c91c877069129930642
# k8s 관리를 위한 사용자(현재 root 사용자) 설정
echo $HOME
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
# CNI - calico install : Pod 대역 자동으로 인식 (명령어 한 줄씩)
curl -O https://docs.projectcalico.org/manifests/calico.yaml
sed -i 's/policy\/v1beta1/policy\/v1/g' calico.yaml
kubectl apply -f calico.yaml
# calicoctl install
curl -o kubectl-calico -O -L "https://github.com/projectcalico/calicoctl/releases/download/v3.19.1/calicoctl"
chmod +x kubectl-calico
mv kubectl-calico /usr/bin
# Source the completion script in your ~/.bashrc file
echo 'source <(kubectl completion bash)' >>~/.bashrc
echo 'source <(kubeadm completion bash)' >>~/.bashrc
# alias kubectl to k
echo 'alias k=kubectl' >> ~/.bashrc
echo 'complete -F __start_kubectl k' >>~/.bashrc
* 본인 VMnet8(NAT)의 IP 대역대에 맞게 수정하여 적용
* 출력되는 해시값이 다 다르기 때문에 본인 커맨드 창에 뜬 명령어를 긁어야 함
노드 상태 확인 명령어들
watch -d -n 2 "kubectl get node"
kubectl get node
kubectl get node -w
kubectl-calico node status
kubectl describe node k8s-w1
kubectl get nodes -o wide
조금 시간이 지난 후 wide 명령어를 쳐서 STATUS가 전부 Ready 상태로 올라와 있으면 설정 성공.

이 4개의 서버는 calico라는 네트워크를 통해 하나의 클러스터로 묶여 있는 상태이다.
kubectl Commands Cheat Sheet
https://kubernetes.io/ko/docs/reference/kubectl/cheatsheet/
kubectl 치트 시트
이 페이지는 일반적으로 사용하는 kubectl 커맨드와 플래그에 대한 목록을 포함한다. Kubectl 자동 완성 BASH source <(kubectl completion bash) # bash-completion 패키지를 먼저 설치한 후, bash의 자동 완성을 현재
kubernetes.io
'IT > Kubernetes' 카테고리의 다른 글
| [Lab] Kubernetes Pod & YAML file (0) | 2021.10.29 |
|---|---|
| Kubernetes Components & Operation (0) | 2021.10.29 |
| [Lab] Kubernetes Pod YAML file / Namespace (0) | 2021.10.28 |
| Kubernetes 기능과 용어 (0) | 2021.10.27 |