WAF (Well Architected Framework)
Web Application Firewall과 헷갈리지 말자.
설계를 검토해주는 역할을 한다.
보안, 안전성, 비용 최적화, 성능 효율성, 운영 우수성 5가지 항목을 확인.
대규모 아키텍처 다이어그램

S3 vs. EBS
| 기준 | S3 | EBS |
| Level(위치) | Region Level | AZ Level |
| Level(파일 단위) | Object Level | Block Level |
| 단위 당 용량 | 5TB | 16TB |
| 비용 지불 | On-demand | Provisioning한 만큼 |
| 온프레미스로 치면 | NAS | DAS |
| 변경 사항 적용 | 파일 전체 Rebuild | 변경된 부분만 업데이트 |
| 용도 | AMI, EBS 백업 | 인스턴스 스토리지 |
| 종속 여부 | 독립적 | 단일 인스턴스에 종속 |
S3 (Simple Storage Service)
Region Level로 만들 수 있는 Web 기반의 스토리지 서비스.
위 다이어그램에 있는 양동이 모양의 '정적 자산'이 바로 이 S3이다.
S3 안에 여러 개의 Bucket이 있고, Bucket 안에 Object 단위로 파일을 저장한다.
업로드한 파일의 일부만 변경되어도 전체 파일을 처음부터 다시 업로드해야 하므로 S3에는 정적인 파일을 저장하는 편이 좋다(WORM : Write Once Read Many).
주로 온프레미스, AMI, EBS의 백업 데이터를 저장하며, Data Lake로써 머신 러닝 등에 사용될 수도 있다.
병렬(Load Balancing)로 읽기/쓰기가 가능하다.
1. 파일 1개 당 5TB 이하
2. 업로드 파일 갯수 무제한
3. 스토리지 전체 사이즈 무제한
4. 업로드 횟수 무제한
이라는 특징을 가지고 있다. 업로드 관련 기능은 무료이지만 스토리지로부터 데이터를 GET할 때 비용이 발생한다.
S3 Bucket Policy
Permissions의 Bucket Policy에 JSON 형식으로 Bucket 별 액세스 제어 정책을 정의할 수 있다.
디폴트로는 비공개이며, 외부로부터의 모든 접근 허용 또는 일부 접근 허용 등의 설정이 가능하다.
Amazon S3 Transfer Acceleration
파일의 근원지로부터 S3에 업로드 되기까지 100% 인터넷 회선을 통하는 대신 이동 과정 중간부터는 Amazon CloudFront(One of Edge Location Features)를 이용해 Amazon Backbone Network를 통한 보다 안전하고 신속한 데이터 이동이 가능하다.
AWS Physical Data Transfer Solutions
10TB 초과의 대용량 데이터를 더 빨리 전송할 수 있는 물리적 솔루션이다.
AWS Snowball은 기내용 캐리어 정도 크기의 저장소이다. 약 80TB의 데이터를 물리적으로 운송할 수 있다.
AWS Snowmobile은 대형 트럭 크기의 데이터 트럭이다. 약 100PB의 데이터를 물리적으로 운송할 수 있다.
S3 4 Tiers
S3 Standard
S3 Standard IA (Infrequent Access)
S3 One Zone IA
S3 Glacier (Backup)
아래로 갈 수록 저장 비용↓ 검색 비용 및 속도↓
Glacier는 신속 검색 5분, 표준 검색 3~5시간, 대량 검색 5~12시간이 소요된다.
S3 Intelligent Tiering : AWS에서 자동으로 데이터들을 티어링한다.
ILM (Information Lifecycle Management)
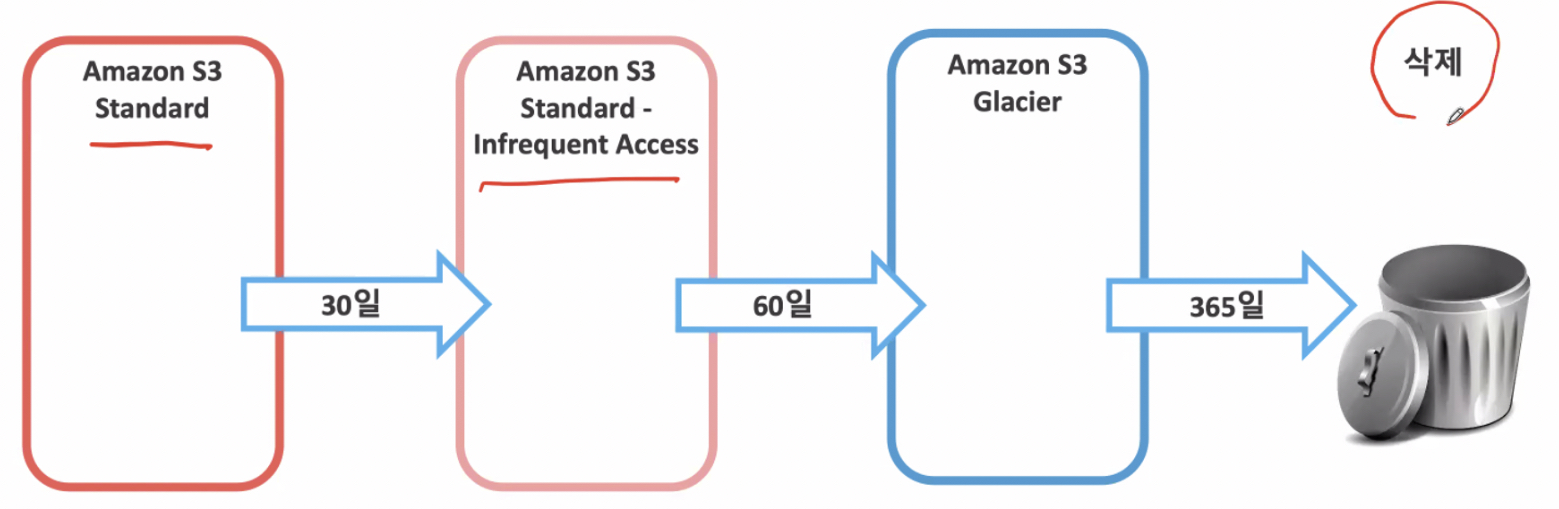
Amazon S3 수명 주기 정책을 사용하면 생성 후 기간을 기준으로 객체를 삭제 또는 이동할 수 있다.
EBS (Elastic Block Store)
하나의 인스턴스에 Attach 되어 종속되어지는 스토리지이다. EBS 1개 당 최대 16TB까지 저장 가능하다.
외장 하드를 구매할 때와 같이 리소스를 Provisioning할 때 그만큼 지불한다.
인스턴스의 데이터 저장용으로 실제 물리적 호스트의 Local Storage 이용 시 인스턴스가 멈췄다가 다시 시작될 경우 다른 물리적 호스트에서 실행될 것이기 때문에(같은 AZ 내일 뿐) 휘발성인 Local Storage가 아닌 별도의 Storage Farm에 있는 EBS를 인스턴스에 매핑시켜 데이터를 저장하게 한다(네트워크를 통한 연결).
Database on AWS
DB 결정 시 고려할 사항으로는 확장성, 총 스토리지 요구 사항, 객체 크기 및 유형, 내구성이 있다.
DB - RDS (Relational Database Service)
AWS에서 관계형 데이터베이스는 Oracle DB, MS-SQL Server, MySQL, MariaDB, PostgreSQL, Aurora 총 6가지를 사용할 수 있다. 이 중 Aurora는 AWS에서 자체 개발한 DB로 완전관리형 데이터베이스이며, MySQL, PostgreSQL과 호환이 가능하다. Aurora를 플랫폼으로 MySQL 사용 시 기존의 최대 5배 처리량, PostgreSQL의 경우 최대 3배.
수직적으로 리소스 조절(Scale Up/Down).
RDS Security
I/O 경합을 막기 위해 Read Replica를 만들어 읽기 부하를 분산시킬 수 있다.
Amazon Aurora는 15개, 나머지 5가지 RDB는 5개까지 Read Replica를 만들 수 있다.
저장 시 KMS를 이용해서 암호화. 통신 시 SSL 암호화 사용.
DB - NoSQL
Document DB : MongoDB
GraphDB : Amazon Neptune, Cassandra
Key-Value DB : Amazon DynamoDB, Redis
DynamoDB는 완전관리형 비관계형 데이터베이스 서비스이다.
Amazon의 전자상거래 서비스에서 일어나는 많은 트랜잭션을 처리하기 위해 개발되었다.
이벤트 중심 프로그래밍(서버리스 컴퓨팅)이다.
수평적으로 리소스 조절(Scale In/Out).
Eventually Consistance Read(DynamoDB default) : 레이턴시 최소화. 게임 등에서 사용한다.
Strongly Consistance Read : 금융권 등에서 사용. 계좌의 잔고가 동기화되지 않으면 큰일이므로 강력하게 읽기 일관성을 정의한다.
DynamoDB Security
Row, Column 등 모든 것에 대해 액세스 권한 부여 가능.
저장 시 KMS를 이용해서 암호화. 통신 시 SSL 암호화 사용.
AWS DMS (Database Migration Service)
AWS는 대부분의 상용 및 오픈 소스 데이터베이스와의 마이그레이션을 지원.
데이터베이스가 너무 클 경우 AWS Snowball Edge(Snowball + Computing Resource)와 연동해 마이그레이션 할 수 있다.
AWS Schema Conversion Tool
이종 마이그레이션의 경우 AWS SCT를 통해 데이터베이스 엔진을 변환해 마이그레이션이 가능하다.
'IT > AWS 공인 교육' 카테고리의 다른 글
| Systems Operations on AWS - Module 1~2 (0) | 2021.11.29 |
|---|---|
| Architecting on AWS - 03 (0) | 2021.11.13 |
| Architecting on AWS - 04 (0) | 2021.11.13 |
| Architecting on AWS - 02 (0) | 2021.11.11 |
| AWS Technical Essentials (0) | 2021.11.09 |