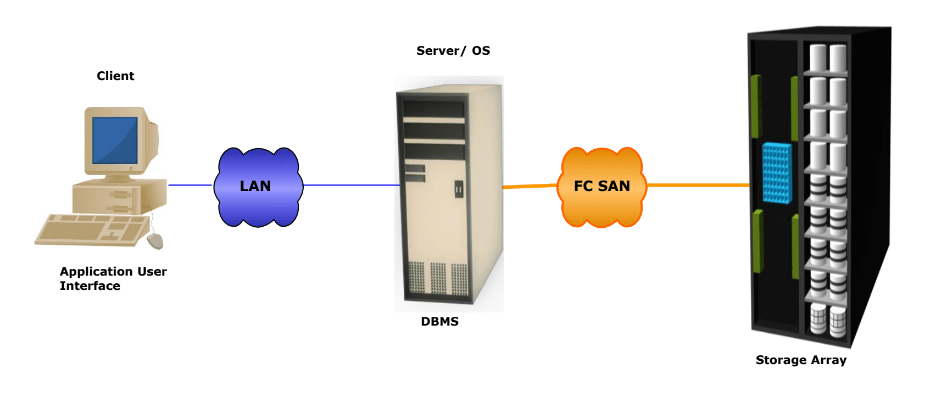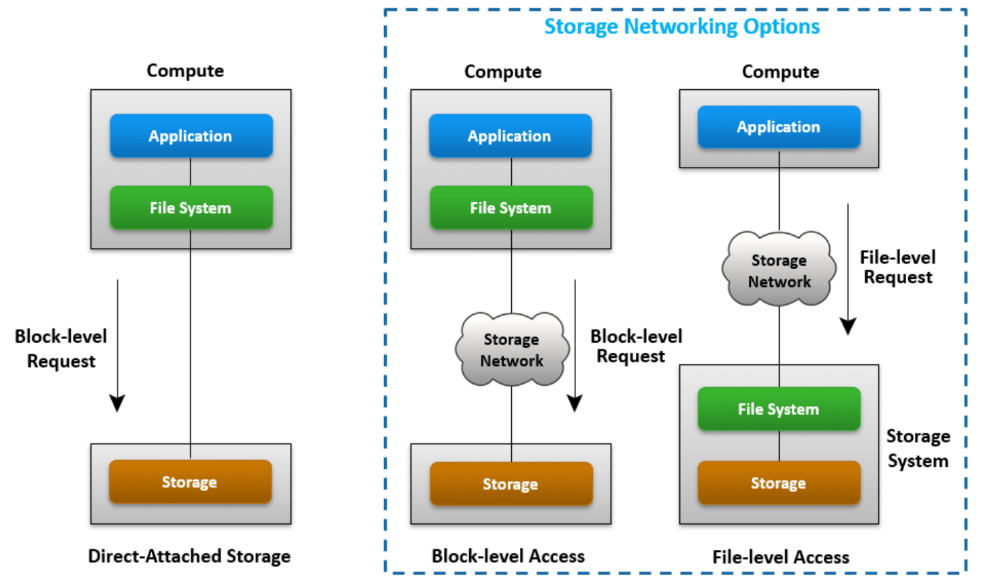
위 그림으로 3가지 형태의 스토리지 사용 방식을 확인할 수 있다.
DAS (Direct-Attached Storage) : Block-level Access
DAS는 스토리지가 직접 호스트에 연결된 구성이다. 호스트의 내부 디스크 드라이브와 직접 연결된 외부 스토리지 어레이가 DAS의 예이다.
Internal DAS
- 스토리지 디바이스가 직렬 또는 병렬 버스로 호스트에 연결된다.
External DAS
- 호스트는 외부 스토리지 디바이스에 직접 연결되고 데이터는 블록 레벨로 액세스된다.
- 호스트와 스토리지 디바이스 간의 통신은 주로 SCSI나 FC 프로토콜을 사용한다.
Internal DAS와 비교해 External DAS는 디바이스 거리와 개수의 한계를 극복하며 스토리지 디바이스를 중앙 집중적으로 관리할 수 있게 해준다.
DAS의 특징으로는 기본적으로 간단한 구성을 가지고 있으며 초기 투자 비용이 낮다는 점과, 저장 용량을 모두 사용했을 경우 확장이 어려워 서비스 가용성에 문제가 생길 수 있다는 점, 사용하지 않는 리소스를 재할당할 수 없기 때문에 많이 사용되는 Storage Pool과 적게 사용되는 Storage Pool이 나뉜다는 점이 있다.
SAN (Storage Area Network) : Block-level Access
SAN은 스토리지가 네트워크를 통해 호스트에 연결된 구성이다. 호스트에서 파일 시스템을 구동하고 있기 때문에 파일 ↔ 블록 변환은 호스트 측에서 수행하고, 네트워크 상에서 데이터는 블록 레벨로 교환이 이루어진다.
DAS와 비교했을 때 가장 큰 차이점으로는 역시 네트워크가 중간에서 중개 역할을 해주고 있다는 것이다. 때문에 DAS에선 스토리지의 포트 하나 당 호스트 하나만 연결이 가능하지만 SAN, NAS에서는 네트워크를 통해 수많은 호스트에게 연결될 수 있다.
SAN의 예로는 금융권 등 대규모 인프라 등이 있다.
NAS (Network-Attached Storage) : File-level Access
NAS 또한 SAN과 같이 스토리지가 네트워크를 통해 호스트에 연결된 형태이다.
하지만 NAS의 경우는 파일 시스템이 호스트 단이 아닌 스토리지 시스템 단에서 돌아가고 있기 때문에 호스트 측에선 파일 단위로 데이터를 송수신할 수 있으며, 스토리지 시스템 측에서 파일 ↔ 블록 데이터 변환을 수행해서 스토리지에 블록 형태로 저장한다. 때문에 호스트는 운영 체제에 구애받지 않고 스토리지를 이용할 수 있다.
이에 관한 내용은 다른 포스트에서 추가적으로 정리할 계획이다.
'IT > Storage' 카테고리의 다른 글
| Intelligent Storage System with Cache (0) | 2021.10.23 |
|---|---|
| RAID(Redundant Arrays of Independent Disks) (0) | 2021.10.18 |
| Application / LVM / Virtualization / Connectivity (modules 02) (0) | 2021.10.12 |
| 데이터 센터 및 클라우드 가상 환경 (modules 01) (0) | 2021.10.12 |