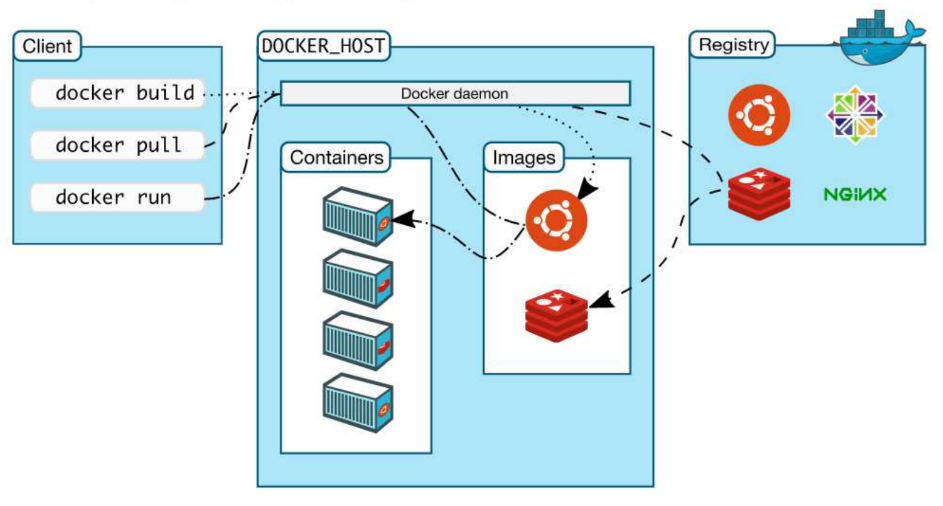
도커 컨테이너 이미지는 운영체제에 구애받지 않고, 새롭게 패키지를 설치할 필요도 없으며, 각종 라이브러리에 대한 의존성의 문제 또한 걱정할 필요가 없다. 만든 컨테이너를 다른 서버로 그대로 옮겨다 놓으면 환경, 모듈 등이 그대로 적용되기 때문에 별도의 환경설정도 필요하지 않다.
도커 컨테이너들은 HostOS로부터 GuestOS로 물리적 리소스를 1/n로 나누어 할당받는 것이 아닌 HostOS의 리소스를 다이렉트로 접근해 모든 컨테이너가 공유하며 사용하기 때문에 다른 가상화 방법에 비해 속도가 매우 빠르고 효율적이다.
도커는 Layered File System 기반이다. 마치 포토샵처럼 레이어 단위로 컨테이너 이미지를 생성하며, 이 컨테이너들은 서버 위에서 각각 하나의 프로세스처럼 작동하지만 컨테이너 자신은 스스로가 운영체제인 것처럼 생각한다.
각 도커 컨테이너는 서로 간에 절대적으로 격리(Isolated)되어 있어 한 컨테이너에 어떤 변화가 발생하더라도 다른 컨테이너에 영향을 주지 않는다.
Registry, Images, Containers, Commands and Daemon in Docker
Public과 Private Registry 중 Public Repository를 Docker Hub라고 부르며, Docker Hub에서 이미지를 올리는 것을 Push, 이미지를 받아 오는 것을 Pull이라고 한다. Pull한 이미지는 /var/lib/docker/overlay2에 저장된다.
Build는 직접 이미지를 생성하는 것인데 여러가지 베이스 환경을 설정해서 이미지 파일을 만든 후에 Run을 하여 프로세스에 올려 컨테이너로 만들거나 Docker Hub로 Push 할 수 있다.
Run은 이미지를 실행하는 명령어인데 이미지가 없을 경우 Pull로 레지스트리에서 이미지를 받아온 후 Run, Start까지 한다. Run을 하게 되면 최대 3가지 처리가 동시에 이루어지고 이미지가 비로소 컨테이너가 되고 프로세스에 올라가게 된다.
실행되고 있는 컨테이너를 Commit해서 현 상태를 이미지로 만들어 Docker Hub로 Push 할 수 있다.
메모리에 올라간 컨테이너를 Kill하면 컨테이너의 프로세스가 종료된다.
메모리에 올라가면 컨테이너(read/write), 올라가지 않은 상태면 이미지(read only)이다.
이 모든 것을 백그라운드에서 실행하고 관리하는 서비스를 dockerd(Docker Daemon)이라고 한다.
기본적으로 하나의 Pod 당 1개의 컨테이너를 갖게 하는 걸 권장한다. 사이드카로 보조 컨테이너를 넣어 2개의 컨테이너를 돌아가게 하는 경우도 있지만, 3개부터는 권장하지 않는다.
쿠버네티스에서는 NAT 통신 없이도 Pod 고유의 IP + 컨테이너 별 Port 주소를 통해 각 컨테이너에 접근할 수 있다. 같은 Pod 내의 컨테이너들은 사실 상 모두 같은 IP 주소를 가진 상태이기에 서로 localhost와 개별 포트넘버를 통해 네트워크 접근을 한다.
같은 Pod 내의 컨테이너들은 반드시 동일 노드에 할당되며 동일한 생명 주기를 가진다. Pod 삭제 시, 그 Pod 내의 모든 컨테이너가 전부 같이 삭제된다. 또한 모두 같은 볼륨에 연결되어 있어 파일 시스템을 기반으로 서로 파일을 주고 받을 수 있다.
[labels] in [metadata]
# 원래 상태
kubectl get pod mynginx -o yaml
# 라벨 추가
kubectl label pod mynginx hello=world
# 변경점 확인
kubectl get pod mynginx -o yaml
# 라벨 확인
kubectl get pod mynginx --show-labels
# run label이 다른 또 하나의 Pod 생성
kubectl run yournginx --image nginx
# key가 run인 Pod 출력
kubectl get pod mynginx -l run
-l = label
# key가 run, value가 mynginx인 Pod 출력
kubectl get pod mynginx-lrun=mynginx
# 워커 노드1에 라벨 부여
kubectl label node k8s-w1 disktype=ssd
# 워커 노드2에 라벨 부여
kubectl label node k8s-w2 disktype=hdd
# 워커 노드3에 라벨 부여
kubectl label node k8s-w3 disktype=hdd
# disktype에 대해 노드들의 라벨 확인
kubectl get node --show-labels | grep disktype
# 새로 만들 Pod(node-selector)의 yaml 파일 생성
nano node-selector.yaml
# node-selector.yaml
apiVersion: v1
kind: Pod
metadata:
name: node-selector
spec:
containers:
- name: nginx
image: nginx
# 특정 노드 라벨 선택
nodeSelector:
disktype: ssd
# nodeSelector 프로퍼티로 인해 이 Pod는 disktype이 ssd인 노드에서 실행될 것이다.
# node-selector Pod 생성
kubectl apply -f node-selector.yaml
# Pod가 어느 노드에서 실행되고 있는지 확인 : disktype을 ssd로 지정해뒀던 k8s-w1에서 실행되고 있을 것이다.
kubectl get pod node-selector -o wide
# node-selector.yaml 수정
nano node-selector.yaml
# node-selector.yaml
apiVersion: v1
kind: Pod
metadata:
name: node-selector
spec:
containers:
- name: nginx
image: nginx
# 특정 노드 라벨 선택
nodeSelector:
disktype: hdd
API 서버는 쿠버네티스 API를 노출하는 쿠버네티스컨트롤 플레인컴포넌트이다. API 서버는 쿠버네티스 컨트롤 플레인의 프론트 엔드이다.
쿠버네티스 API 서버의 주요 구현은kube-apiserver이다. kube-apiserver는 수평으로 확장되도록 디자인되었다. 즉, 더 많은 인스턴스를 배포해서 확장할 수 있다. 여러 kube-apiserver 인스턴스를 실행하고, 인스턴스간의 트래픽을 균형있게 조절할 수 있다.
etcd
모든 클러스터 데이터를 담는 쿠버네티스 뒷단의 저장소로 사용되는 일관성·고가용성 키-값 저장소.
쿠버네티스 클러스터에서 etcd를 뒷단의 저장소로 사용한다면, 이 데이터를백업하는 계획은 필수이다.
논리적으로, 각컨트롤러는 분리된 프로세스이지만, 복잡성을 낮추기 위해 모두 단일 바이너리로 컴파일되고 단일 프로세스 내에서 실행된다.
이들 컨트롤러는 다음을 포함한다.
노드 컨트롤러: 노드가 다운되었을 때 통지와 대응에 관한 책임을 가진다.
레플리케이션 컨트롤러: 시스템의 모든 레플리케이션 컨트롤러 오브젝트에 대해 알맞은 수의 파드들을 유지시켜 주는 책임을 가진다.
엔드포인트 컨트롤러: 엔드포인트 오브젝트를 채운다(즉, 서비스와 파드를 연결시킨다.)
서비스 어카운트 & 토큰 컨트롤러: 새로운 네임스페이스에 대한 기본 계정과 API 접근 토큰을 생성한다.
Node Components
kubelet
클러스터의 각노드에서 실행되는 에이전트. Kubelet은파드에서컨테이너가 확실하게 동작하도록 관리한다.
Kubelet은 다양한 메커니즘을 통해 제공된 파드 스펙(PodSpec)의 집합을 받아서 컨테이너가 해당 파드 스펙에 따라 건강하게 동작하는 것을 확실히 한다. Kubelet은 쿠버네티스를 통해 생성되지 않는 컨테이너는 관리하지 않는다.
kube-proxy
kube-proxy는 클러스터의 각노드에서 실행되는 네트워크 프록시로, 쿠버네티스의서비스개념의 구현부이다.
kube-proxy는 노드의 네트워크 규칙을 유지 관리한다. 이 네트워크 규칙이 내부 네트워크 세션이나 클러스터 바깥에서 파드로 네트워크 통신을 할 수 있도록 해준다.
kube-proxy는 운영 체제에 가용한 패킷 필터링 계층이 있는 경우, 이를 사용한다. 그렇지 않으면, kube-proxy는 트래픽 자체를 포워드(forward)한다.
Cloud controller manager
클라우드별 컨트롤 로직을 포함하는 쿠버네티스컨트롤 플레인컴포넌트이다. 클라우드 컨트롤러 매니저를 통해 클러스터를 클라우드 공급자의 API에 연결하고, 해당 클라우드 플랫폼과 상호 작용하는 컴포넌트와 클러스터와만 상호 작용하는 컴포넌트를 구분할 수 있게 해 준다.
cloud-controller-manager는 클라우드 제공자 전용 컨트롤러만 실행한다. 자신의 사내 또는 PC 내부의 학습 환경에서 쿠버네티스를 실행 중인 경우 클러스터에는 클라우드 컨트롤러 매니저가 없다.
kube-controller-manager와 마찬가지로 cloud-controller-manager는 논리적으로 독립적인 여러 컨트롤 루프를 단일 프로세스로 실행하는 단일 바이너리로 결합한다. 수평으로 확장(두 개 이상의 복제 실행)해서 성능을 향상시키거나 장애를 견딜 수 있다.
다음 컨트롤러들은 클라우드 제공 사업자의 의존성을 가질 수 있다.
노드 컨트롤러: 노드가 응답을 멈춘 후 클라우드 상에서 삭제되었는지 판별하기 위해 클라우드 제공 사업자에게 확인하는 것