RAID 개요
RAID란 간단히 정리하면 여러 개의 디스크 드라이브를 모아서 하나의 호스트에 연결해 사용할 수 있게 하는 디스크 관리 솔루션이다.
RAID가 처음 등장하게 된 배경은 1980년대 후반에 비즈니스 환경에서의 컴퓨터 사용이 늘어나고 새로운 애플리케이션과 데이터베이스가 대거 등장하면서 스토리지 용량과 성능에 대한 수요가 빠르게 증가함에 따라 낮은 비용으로 고성능의 스토리지를 이용하기 위해서였다.
때문에 RAID의 논문이 처음 발표되었을 당시엔 Independent(독립적인)가 아닌 Inexpensive(저렴한)이었지만 스토리지 기술이 점차 발전하면서 RAID 기술의 목적이 변화하고 실질적 비용도 저렴하다고 할 수 없게 되어서 변경되었다.
RAID의 구현 방법
RAID를 구현하는 방법으로는 Software RAID와 Hardware RAID가 있는데, 소프트웨어 방식은 CPU와 메모리 자원을 부가적으로 사용하기 때문에 전체 시스템 성능에 영향을 끼치고 운영 체제에 따라 호환성의 문제가 있을 수 있어 잘 사용되지 않는다. 하드웨어 방식의 경우는 호스트나 어레이에 전용 하드웨어 컨트롤러를 사용하게 되며, 주로 이(하드웨어) 방식으로 RAID를 구현한다.
RAID의 레벨 (표준 : 0~6)
RAID 0 : Striped array with no fault tolerance(내결함성)
RAID 1 : Disk Mirroring
Nested RAID (1+0, 0+1, etc.)
RAID 3 : 전용 Parity Disk가 있는 Parallel access array
RAID 4 : 전용 독립 디스크 액세스를 사용하는 Parity Disk가 있는 Striped array
RAID 5 : 분산 독립 디스크 액세스를 사용하는 Parity가 있는 Striped array
RAID 6 : Dual 독립 디스크 액세스를 사용하는 분산 Parity가 있는 Striped array
- Even-Odd(짝수 오드) 또는 Reed-Solomon 알고리즘을 통해 패리티를 계산한다.
RAID 7 : 향상된 데이터 I/O 작업 및 데이터 캐싱을 위한 실시간 임베디드 운영 체제 및 프로세서를 포함한다.
RAID의 기본적인 기술 3가지 : Striping, Mirroring, Parity

Striping : RAID 0
Striping은 Host에서 입력된 데이터를 RAID Controller에서 디스크 드라이브 갯수만큼 쪼개고(Strip) 각 디스크에 그 데이터의 조각(Stripe)들을 저장해 두는 기술이다. 여러 개의 디스크를 통해 병렬적으로 I/O가 가능하기 때문에 성능적 측면에서 유리하지만, 디스크 중 하나가 사용할 수 없게 되면 원래 데이터의 일부를 그대로 유실하는 것이기 때문에 내결함성 측면에서의 단점을 가지고 있다.

Mirroring : RAID 1
Mirroring은 Host에서 입력된 데이터를 RAID Controller에서 복제 과정을 거쳐 두 개의 디스크 드라이브에 각각 저장하게 된다.
하나의 디스크에서 데이터의 변경이 일어나면 다른 쪽의 디스크에서도 똑같이 데이터가 변하기 때문에 정적인 상태를 저장해두는 백업의 개념과는 다르다. 미러링은 원래 운용하던 디스크가 고장났을 경우 다른 하나로 계속 운용할 수 있게 한다는 내결함성을 보장하기 위한 장치라고 볼 수 있다.
Striping과는 달리 내결함성을 충족하지만 복제 과정에서 시간이 소요되기 때문에 쓰기(Input)의 속도가 떨어진다.

Parity : RAID 3
Parity는 Host에서 입력된 데이터를 RAID Controller에서 Parity값을 구하는 계산을 수행한 후 Parity값만을 저장할 Parity Disk에 구한 Parity값을 입력하고, 나머지 디스크에 Striping과 같이 데이터들을 쪼개서 저장한다.
이 Parity값을 통해 고장난 다른 디스크의 정보를 복구할 수 있지만 2개 이상이 동시에 고장나거나 Parity Disk 자신이 고장난 경우에는 복구가 불가능하다는 특징이 있다.
Nested RAID & RAID 5
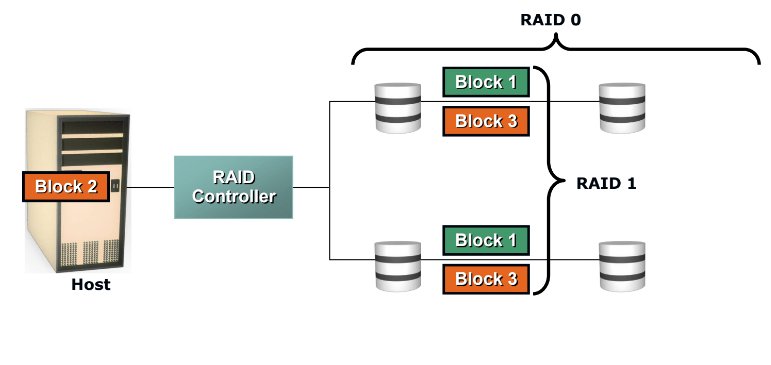
Nested RAID (1+0)
Nested RAID는 일종의 하이브리드 RAID 방식으로 주로 RAID 0 + RAID 1이나 RAID 1 + RAID 0 조합을 사용한다. 0+1의 경우는 스트라이핑이 미러링보다 앞서 이루어지기 때문에 디스크 손상 시 복구하는 과정이 1+0 대비 복잡하고 특별한 이점이 없어 잘 사용되지 않는다.
1+0의 경우는 위의 그림과 같이 미러링이 먼저 이루어진 후 스트라이핑을 통해 데이터를 분산 저장하는 방식인데, I/O 처리 속도와 가용성 두 가지를 전부 챙길 수 있기 때문에 효율적이다.

RAID 5
RAID 5는 패리티 비트 활용 방식인 RAID 3의 확장형이라고 할 수 있다. RAID 3의 단점은 2개 이상의 디스크가 고장나거나 Parity Disk가 고장나게 되면 복구가 불가능하다는 것이었는데, RAID 5에서는 계산된 패리티 비트를 2개의 디스크에 나누어 저장함으로써 RAID 3보다 뛰어난 가용성을 가지게 되었다.
애플리케이션 IOPS 계산

애플리케이션의 RAID 레벨 결정
RAID 1+0
- 소규모, 랜덤 및 쓰기 작업이 많은(일반적으로 30% 이상 쓰기) I/O 프로파일을 사용하는 애플리케이션에 적합
- ex) OLTP, RDBMS
RAID 3
- 대규모 환경에서 순차적으로 읽고 쓰기 작업이 많은 환경
- ex) data backup, Multimedia streaming
RAID 5 / 6
- 소규모, 랜덤 워크로드(일반적으로 30% 미만 쓰기)
- ex) email, RDBMS
RAID Comparison
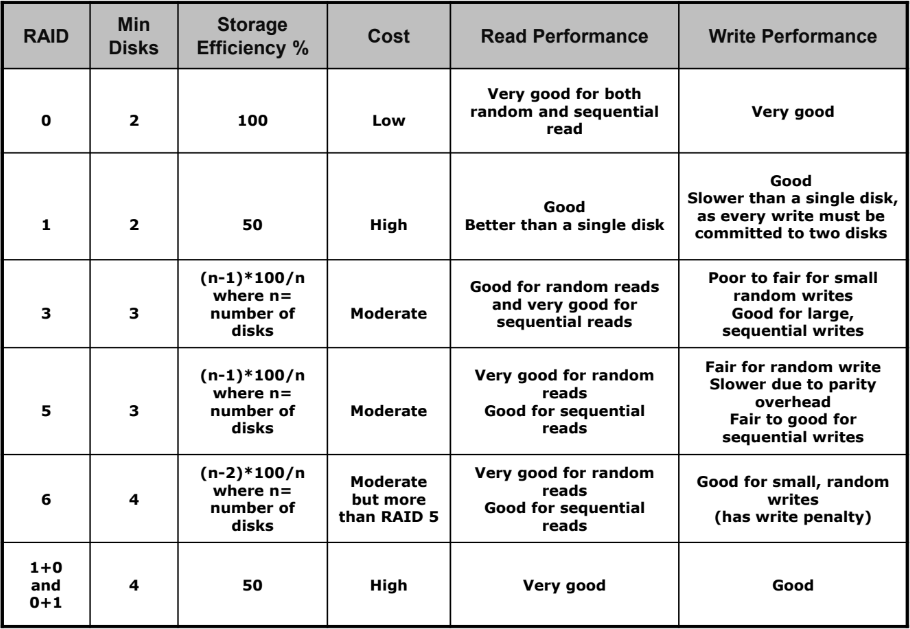
아래 표를 통해 각 RAID 별 필요한 최소 디스크 개수, 스토리지 효율 등의 정보를 확인하고 비교할 수 있다.
Hot Spare
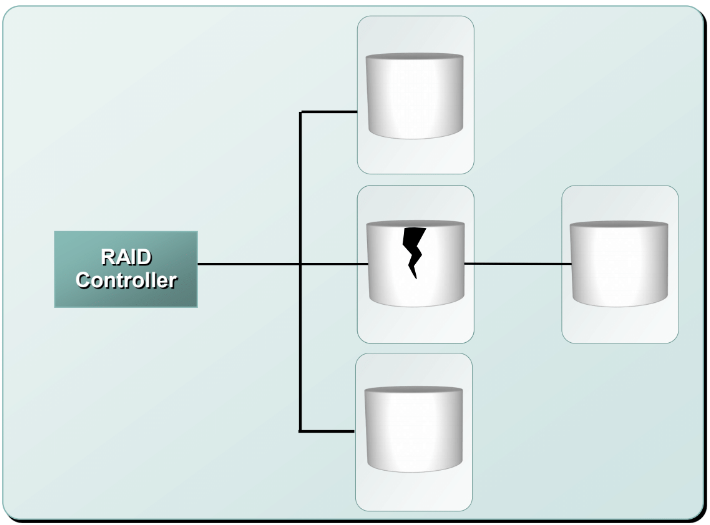
핫 스페어는 고장난 디스크를 잠시 대신하기 위한, RAID 어레이에 있는 여분의 드라이브를 말한다.
- 패리티 RAID를 사용하는 경우 : RAID 집합의 살아 있는 디스크 드라이브의 데이터와 패리티로부터 데이터를 복구해 핫 스페어에 저장한다.
- 미러링 RAID를 사용하는 경우 : 미러의 데이터를 핫 스페어에 복사한다.
새 디스크 드라이브를 시스템에 추가하면 핫 스페어의 데이터를 새 드라이브에 복사한다. 데이터의 복사가 완료되면 핫 스페어는 다시 대기 상태로 돌아가고 다음 고장 드라이브를 대처할 준비를 한다.
'IT > Storage' 카테고리의 다른 글
| Intelligent Storage System with Cache (0) | 2021.10.23 |
|---|---|
| Block-level Access & File-level Access (with DAS / SAN / NAS) (0) | 2021.10.13 |
| Application / LVM / Virtualization / Connectivity (modules 02) (0) | 2021.10.12 |
| 데이터 센터 및 클라우드 가상 환경 (modules 01) (0) | 2021.10.12 |